⭐ Kubernetes
💡 목차
기본적은 내용은 알고 있으므로 간단한 활용법만 작성
1. Kubernetes 구성
2. Kubernetes Resources
2-1. Pod
2-2. Namespace
2-3. Labels
2-4. Deployments (replicaset, replication controller)
2.5. Statefulset
2-6. DaemonSet
2-7. Service
2-8. ServiceDiscovery
2-9. ConfigMap & Secret
2-10. Volume - emptyDir
2-11. Volume - hostPath
2-12. Volume - NFS
2-13. Volume - static
2-14. Volume - Dynamic
2-15. RBAC
2-16. HPA
3. Kubernetes Use Case
3-1. Helm
3-2. Prometheus
3-3. Diamanti
3-4. Diamanti HCI
3-5. Diamanti Ultima Card
3-6. Kubernetes CNI Overlay Network
3-7. Kubernetes CNI SR-IOV
3-8. Kubernetes CSI Storage
3-9. Diamanti QoS
3-10. Diamanti Port Group
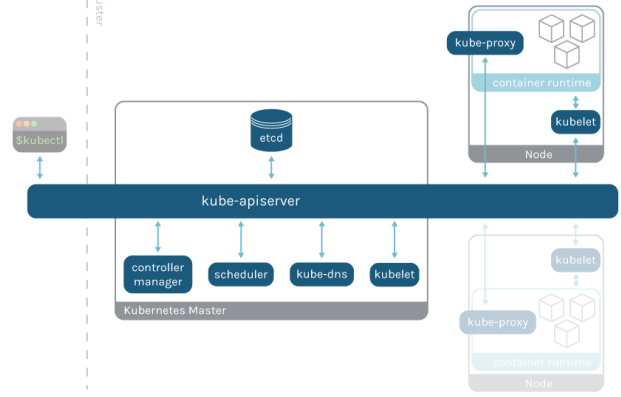
📌 1. Kubernetes 구성
- API-Server
- Control Plane(Master) 의 중심 컴포넌트, 모든 역할의 출발점
- ETCD
- 모든 클러스터의 데이터가 저장 되어 있는 Key-Value Database
- Scheduler
- 새로 생성된 Pod를 감지하고, 컨테이너를 생성할 노드를 선택
- Kubelet
- 각 노드의 실행 에이전트, Node & Pod의 Health Check를 담당
- Kube-Proxy
- 각 노드의 실행되는 네트워크 프록시
# Kubernetes Resource 확인
kubectl api-resources
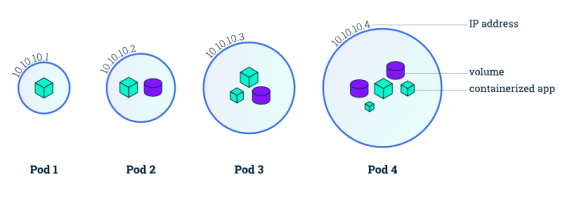
📌 2-1 Pod
- 1개 이상의 컨테이너를 모아놓은 것으로 쿠버네티스 어플리케이션의 최소 단위
- Kubectl 기반의 Pod 생성
# Pod 생성
kubectl run [pod-name] --image=[image-name] --dry-run=client -o yaml > [yaml-name].yaml
# Yaml 파일 기반 생성
kubectl create / apply -f [yaml-name].yaml
# Pod 접속
kubectl exec -it [pod-name] /bin/bash
# Pod Network Check
kubectl get pods -o wide
curl [pod-ip]- Pod의 Lifecycle
- Pending 단계로 시작해서 컨테이너 실행이 성공하면 OK, 실패시 Pendind & Failed
- Pod 실행 실패 시 kubectl logs [pod-name] | events 을 입력해 실패 이벤트 로그를 확인
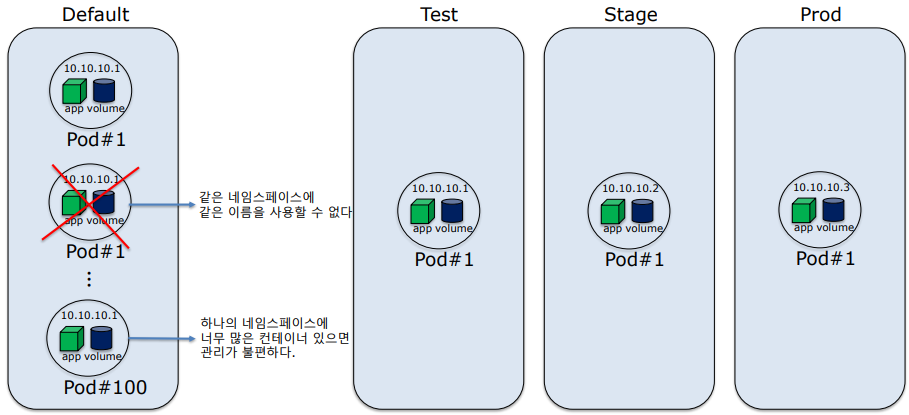
📌 2-2 Namespace
- 물리 클러스터를 기반의 가상 클러스터, 기본 네임스페이스는 default 이다.
- 같은 네임스페이스 내에서 리소스의 이름은 중복 불가능
- Kubectl 기반의 Namespace 생성
# 1. yaml의 metadata 하위 name: 에 지정해도 됨
# 2. 리소스를 생성할때 -n [namespace-name] 으로 옵션 지정도 가능
# 3. kube-node-lease, kube-system, kube-public 네임스페이스는 사용하지 않는게 좋음
# Namespace 생성
kubectl create namespace [namespace-name]
# Namespace 조회
kubectl get ns
# 기본 Namespace의 모든 Resource 조회
kubectl get all -o wide -n default
# yaml 기반 생성
apiVersion: v1
kind: Namespace
metadata:
name: workns
# 현재 사용중인 기본 네임스페이스 변경
kubectl config set-context --current --namespace=[namespace-name]
# 변경된 네임스페이스 확인
kubectl config view | grep namespace
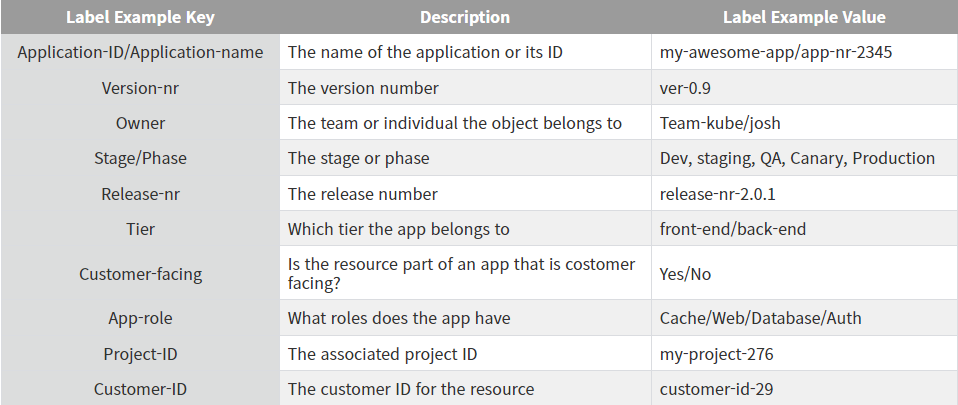
📌 2-3 Labels
- 쿠버네티스 객체를 식별할 수 있고, 그룹으로 구성 가능
- 좋은 Use-Case는 Pod에 배치된 어플리케이션을 기반으로 그룹핑 하는것과
환경이나 고객 & 팀 & 소유자 & 릴리즈 버전에 따라 그룹화 하는 다양한 레이블 규칙 개발 가능 - 리소스를 생성할때 레이블을 무조건 지정해서 사용하기
- 커밋 컨벤션 처럼 레이블 컨벤션을 도입하기
- Pob Template 활용, 파드 템플릿은 쿠버네티스 컨트롤러에서 파드를 생성하기 위한 manifest 파일임
- 공통적인 옵션들에 대한 레이블 리스트 만들기 (어플리케이션id, 버전, 소유자, 환경, 릴리즈 버전 등)
- 더 광범위한 레이블 리스트 만들기
- 쿠버네티스에서 추천하는 레이블 사용
# 쿠버네티스 추천 레이블
apiVersion: v1
kind: Pod
metadata:
labels:
app.kubernetes.io/name: my-pod
app.kubernetes.io/instance: Auth-1a
app.kubernetes.io/version: “2.0.1”
app.kubernetes.io/component: Auth
app.kubernetes.io/part-of: my-app
app.kubernetes.io/managed-by: helm
# Lable 수정
labels:
app: mynginx # 이 부분 수정 후
or
metadata:
name: nginx-pod
labels: # 이 부분
app: nginx
team: kube-team
environment: staging
spec:
replicas: 3
selector:
matchLabels: # 이 부분
app: nginx
template:
metadata:
labels: # 이 부분
app: nginx
kubectl apply -f [pob-name].yaml
# Pod에 새로운 레이블 추가
kubectl label pod [pod-name] version=0.2
# 레이블 삭제
kubectl label pod [pod-name] version # 키 값만 입력
# 레이블 변경 team:kube-team -> team:ops
kubectl label --overwrite pods [pod-name] team=ops
📌 2-4 Deployments
- replicaset의 상위 오브젝트
- 배포 작업의 세분화, 롤링업데이트, revision 등의 기능을 사용 가능
# 생성, --replicas=3 으로 레플리카 수 지정 가능
kubectl create deployment [deploy-name] --image=[image-name] --dry-run=client -o yaml > [yaml-name]
# Yaml 생성
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
# 생성
kubectl apply -f [deployment-name].yaml
# Deployment Update
kubectl set image deployment/[deploy-name] [container-name]=[image-name]:[version]
# revision
kubectl apply -f deployment-nginx.yaml --record * --record : revision Enable
kubectl set image deployment [deploy_name] nginx=nginx:1.11 --record * update image & revision
kubectl rollout history deployment [deploy_name] * revision history 1 전 / 2 최근
kubectl rollout undo deployment [deploy_name] --to-revision=1 * revision 1번으로 rolling update
# rollout 기록에 change-cause 버전 기록
metadata:
annotations:
kubernetes.io/change-cause: [기록할 단어]
# Deployment 배포 일시중지
kubectl rollout pause deployment/[deploy-name]
# Deployment 배포 재시작
kubectl rollout resume deployment/[deploy-name]
# Deployment 전체 Pod 재시작
kubectl rollout restart deployment/[deploy-name]
📌 2-5 StatefulSet
- 어플리케이션의 상태를 저장하고 관리하는 쿠버네티스 오브젝트
- replication controller와 같은 복제본을 가지고 있는 컨트롤러를 의미함
- 기존 Pod를 삭제하고 생성할 때 상태가 유지되지 않는 한계가 있고 삭제-생성을 하면 새로운 가상환경이 된다
하지만 StatefulSet으로 생성되는 Pod는 영구 식별자를 가지고 상태를 유지시킬 수 있다 - StatefulSet을 사용해야 할 때
- 안정적이고 고유한 네트워크 식별자가 필요한 경우
- 지속적인 스토리지를 사용해야하는 경우
- 질서정연한 Pod의 배치와 확장을 원하는 경우
- Pod의 Auto Rolling Update를 사용하기 원하는경
- StatefulSet의 문제점
- StatefulSet과 관련된 볼륨은 삭제되지 않음 (관리 필요)
- Pod의 Storage는 PV나 StorageClass로 Provisining을 수행해야 함
- 롤링 업데이트를 하는 경우 수동으로 복구해야 할 수 있다 (기존 스토리지와 충돌로 인한 어플리케이션 오류)
- Pod Network ID를 유지하기 위해 Headless 서비스 필요 (ClusterIP를 None으로 지정하여 생성 가능)
- Headless 서비스 자체는 IP가 할당이 안되지만 서비스의 도메인 네임을 사용해 각 Pod에 접근 가능하며,
기존의 서비스와 달리 kube-proxy가 밸런싱이나 프록시 형태로 동작하지 않음
📌 2-6 DaemonSet
- 클러스터 전체에서 공통적으로 사용되는 기본 pod를 띄울때 사용하는 컨트롤러
- ex: 로그수집기나 노드를 모니터링하는 pod 등 클러스터 전체에 항상 실행시켜 둬야 하는 pod를 실행할때 사용
- taint와 tolleration을 사용하여 특정 노드들에만 실행가능 (tolleration은 taint보다 우선순위가 더 높다)
# DaemonSet 생성
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: test-elasticsearch
namespace: kube-system
labels:
k8s-app: test-logging
spec:
selector:
matchLabels:
name: test-elasticsearch
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
name: test-elasticsearch
spec:
containers:
- name: container-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
terminationGracePeriodSeconds: 30- apiVersion apps/v1 → 쿠버네티스의 apps/v1 API를 사용
- kind: DaemonSet → DaemonSet의 작업으로 명시
- metadata.name → DaemonSet의 이름을 설정
- metadata.namespace → 네임스페이스를 지정 합니다. kube-system은 쿠버네티스 시스템에서 직접 관리하며 보통 설정 또는 관리용 파드를 설정
- metadata.labels → DaemonSet를 식별할 수 있는 레이블을 지정
- spec.selector.matchLabels → 어떤 레이블의 파드를 선택하여 관리할 지 설정
- spec.updateStrategy.type → 업데이트 방식을 설정
이 코드에서는 롤링 업데이트로 설정 돼었으며 OnDelete 등의 방식으로 변경이 가능
롤링 업데이트는 설정 변경하면 이전 파드를 삭제하고 새로운 파드를 생성 - spec.template.metadata.labels.name → 생성할 파드의 레이블을 파드명: "" 으로 지정
- spec.template.spec.containers → 하위 옵션들은 컨테이너의 이름, 이미지, 메모리와 CPU의 자원 할당
- terminationGracePeriodSeconds 30 → 기본적으로 kubelet에서 파드에 SIGTERM을 보낸 후
일정 시간동안 graceful shutdown이 되지 않는다면 SIGKILL을 보내서 파드를 강제 종료
이 옵션은 그레이스풀 셧다운 대기 시간을 30초로 지정하여 30초 동안 정상적으로 종료되지 않을 경우 SIGKILL을 보내서 강제 종료 시킴

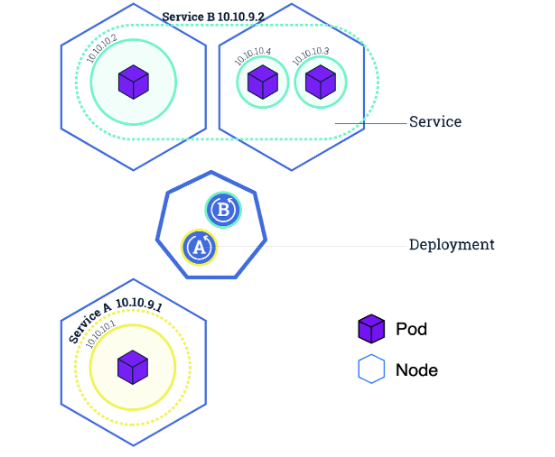
📌 2-7 Service
- 노드의 파드는 기본적으로 외부통신이 안되는 내부망의 환경에 있다
- Service란 Pod의 논리적 집합이며 어떻게 접근할지에 대한 정책을 정의해놓은 것
- Service는 기본적으로 Load Balancing 과 Port Forwarding 기능을 포함한다
- Label Selector를 통해 노출시킬 오브젝트의 레이블을 지정하는 방식이 주로 쓰인다
- 외부에 노출시킬때 4가지 타입이 있다
- ClusterIP (default) - 클러스터 내부 통신용
- NodePort - 노드IP:Port 의 방식을 통해 외부에서 접근 (NAT), 30000번대 포트
- Load Balancer - 외부의 Load Balancer를 사용하는 방법
- ExternalName - kube-dns로 DNS를 이용하는 방법
📌 2-8 Service Discovery
- MSA와 같은 분산 환경은 서비스 간의 원격 호출로 구성이 되며, 원격 서비스 호출은 IP와 포트를 이용하는 방식이 있다
- 클라우드 환경으로 바뀌면서 서비스가 오토 스케일링 등에 의해 동적으로 생성되거나
컨테이너 기반의 배포로 인해 서비스의 IP가 동적으로 변경되는 일이 잦아졌다 - 이때, 서비스의 위치를 알아낼 수 있는 기능이 Service Discovery이다
다음 그림을 보자

- Service A의 인스턴스들이 생성될때, Service A에 대한 주소를 Service Registry에 등록한다
- Service A를 호출하고자 하면 Registry에 A의 주소를 물어보고 등록된 주소를 받아서 그 주소를 호출한다
Service Registry를 구현하는 방법
- 가장 쉬운 방법은 DNS 레코드에서 하나의 호스트명에 여러개의 IP를 매핑시키는것이다
하지만 이 방법은 레코드 삭제시 업데이트 되는 시간 등이 소요되기 떄문에 적절한 방법은 아니다 - 다른 방법으로는 솔루션을 사용하는 방법인데,
ZooKeeper나 etcd와 같은 서비스를 이용할 수 있고 Netflix의 Eureka나 Hashcorp의 Consul과 같은 서비스가 있다
Service Discovery의 종류
Client Side Discovery

생성된 서비스는 Service Registry에 서비스를 등록하고, 서비스를 사용할 클라이언트는 Service Registry에서 서비스의 위치를 찾아 호출하는 방식이다.
장점
- 구현이 비교적 간단
- 클라이언트가 사용 가능한 서비스 인스턴스에 대해 알고있기 때문에 각 서비스별 로드 밸런싱 방법을 선택할 수 있다.
단점
- 클라이언트와 서비스 레지스트리가 연결되어 있어서 종속적이다.
- 서비스 클라이언트에서 사용하는 각 프로그래밍 언어 및 프레임워크에 대해서 클라이언트 측 서비스 검색 로직을 구현해야 한다.
대표적으로 Netflix OSS(Netflix Open Source Software)에서 Client-Side discovery Pattern을 제공하는 Netflix Eureka가 Service Registry 역할을 하는 OSS이다.
Server Side Discovery
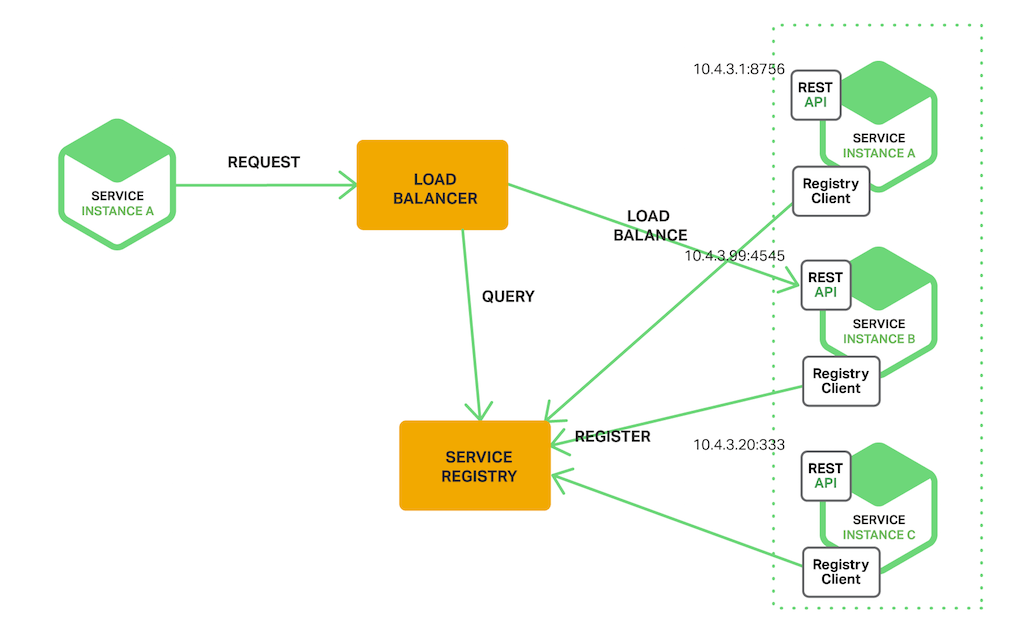
서비스를 사용할 클라이언트와 Service Registry 사이에 일종의 Proxy 서버인 Load Balancer를 두는 방식이다.
클라이언트는 Load Balancer에 서비스를 요청하고 Load Balancer가 Service Registry에 호출할 서비스의 위치를 질의하는 방식이다.
장점
- discovery의 세부 사항이 클라이언트로부터 분리되어있다(의존성↓)
- 분리되어 있어 클라이언트는 단순히 로드 밸런서에 요청만 한다. 따라서 각 프로그래밍 언어 및 프레임 워크에 대한 검색 로직을 구현할 필요가 없다
- 일부 배포환경에서는 이 기능을 무료로 제공한다.
단점
- 로드밸런서가 배포환경에서 제공되어야 한다.
- 제공되어있지 않다면 설정 및 관리해야하는 또 다른 고 가용성 시스템 구성 요소가 된다
AWS의 ELB나 GCP의 로드밸런서가 대표적이다.
Kubernetes에서의 Service Discovery
DNS를 이용하는 방법서비스는 생성되면 [서비스 명].[네임스페이스 명].svc.cluster.local 이라는 DNS 명으로 쿠버네티스 내부 DNS에 등록된다. 쿠버네티스 클러스터 내부에서는 이 DNS 명으로 서비스에 접근이 가능한데, 이때 DNS에서 리턴해주는 IP는 외부IP(External IP)가 아니라 ClusterIP이다.
External IP를 명시적으로 지정하는 방법
다른 방식으로는 외부 IP를 명시적으로 지정하는 방식이 있다. 쿠버네티스 클러스터에서는 이 외부IP를 별도로 관리하지 않기 때문에, 이 IP는 외부에서 명시적으로 관리되어야 한다.
apiVersion: v1
kind: Service
metadata:
name: hello-node-svc
spec:
selector:
app: hello-node
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
externalIPs:
- 80.11.12.11
AWS, GCP가 제공하는 Load Balancer를 이용하는 방법
퍼블릭 클라우드의 경우에는 이 방식보다는 클라우드 내의 로드밸런서를 붙이는 방법을 사용한다.
서비스에 정적 IP를 지정하기 위해서는 우선 정적 IP를 생성해야 한다.
VPC 메뉴의 External IP 메뉴에서 생성해도 되고 CLI 명령줄을 이용해 생성해도 된다.
apiVersion: v1
kind: Service
metadata:
name: hello-node-svc
spec:
selector:
app: hello-node
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
type: LoadBalancer
loadBalancerIP: 생성한 정적 IP
📌 2-9 ConfigMap (Key - Value) & Secret
ConfigMap & Secret
- 어플리케이션을 배포하다 보면 환경에 따라 다른 설정값을 사용하는 경우 사용한다
- Github Actions의 Secret처럼 컨테이너 런타임 시 변수나 설정값을 Pod가 생성될 때 넣어줄 수 있다
- ConfigMap
- Key - Value 형식으로 저장됨
- Config Map을 생성하는 방법은 literal로 생성하는 방법과 파일로 생성하는 2가지 방법이 있다
- ConfigMap이나 Secret에 정의하고, 이 정의해놓은 값을 Pod로 넘기는 2가지 방법이 있다
- 값을 Pod의 환경 변수로 넘기는 방법
- 값을 Pod의 Disk Volume으로 Mount 하는 방법

ConfigMap Literal 생성
- 키:값이 language : java인 ConfigMap이라고 가정한다
- kubectl create cofigmap [name] --from-literal=[key]=[value] 명령으로 생성
- yaml은 data.[key:value] 형식으로 만든다
- 아래 코드는 deployment에 환경변수로 적용한 yaml 설정이다
env:
- name: LANGUAGE
valueFrom:
configMapKeyRef:
name: test-configmap
key: language
ConfigMap File 생성
- profile.properties라는 파일이 있고 설정 파일 형태로 Pod에 공유한다
myname = hello
email = abc@abc.com
address = seoul - kubectl create cofigmap [name] --from-file=[location] 명령으로 생성
- 아래 코드는 deployment에 파일을 환경변수로 적용한 yaml 설정이다
env:
- name: PROFILE
valueFrom:
configMapKeyRef:
name: cm-file
key: profile.properties'Ops > Kubernetes' 카테고리의 다른 글
| Kubernetes의 구성요소 (0) | 2023.02.19 |
|---|---|
| Kubernetes 테스트 환경 구성 (Kubespray & Ansible 구축) (0) | 2023.02.11 |
| CI/CD Pipeline with Jenkins (0) | 2022.08.01 |
| CKA 공부 메모 (0) | 2022.08.01 |
| 클러스터링 (adm,ctl,let) Script (0) | 2022.08.01 |
